
Introduction
Data Science is one of the most exciting fields of the 21st century. The power to understand human voices, recognize faces, understand text, and much more has vast applications across industries. In this article, we’re going to define some of the most important terms in more detail. This is Part I of a series explaining typical Data Science terms.
Data Science
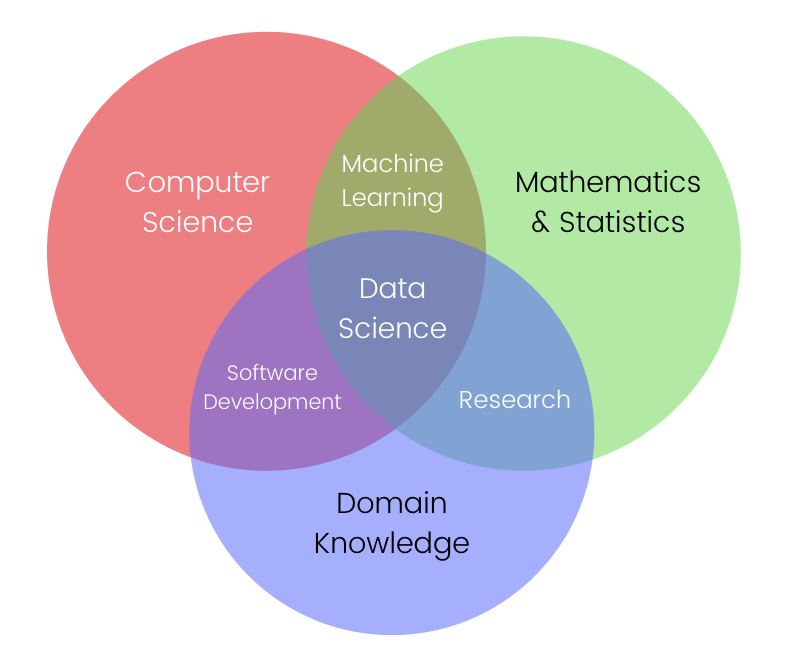
Let’s start with the base of all terminologies: Data Science. Data Science is a multifocal field, consisting of an intersection of Mathematics, Statistics, Computer Science, & Domain Specific Knowledge of a specific field.
It is the application of Mathematics and Statistics on real-world problems to solve them faster using computers. It involves Software Development (the software which solves the problem), Machine Learning (to train the machine using mathematics) and Traditional Research (to make mathematical assumptions of the problem).
Data Science is applied to those problems where traditional algorithms will take too long to solve them, or won’t be able to solve them as accurately. For example, predicting the housing prices of an area, controlling the movements of an autonomous vehicle, recognizing human faces, etc.
Artificial Intelligence (AI)
Artificial Intelligence is a term that is sometimes incorrectly used to refer to all Data Science problems. AI is actually referring to computer systems or programs which are intelligent enough to be able to complete tasks which generally requires human intervention.
A computer system in AI is known as an “intelligent agent”, which takes input from the environment and performs actions which maximize the chances of achieving its goals. Improving the learning, knowledge representation, perception, and object manipulation capability of these “intelligent agents” are the short-term goals of Artificial Intelligence.
Artificial Intelligence is further subdivided into Narrow AI & General AI. Narrow AI is only capable of doing a single task well such as understanding human speech, playing strategic games like Chess or Go, or operating vehicles autonomously. In contrast, a General AI should be capable of completing any task given to it, like a human. The long-term goal of AI is to create an Artificial General Intelligence (AGI).
Machine Learning (ML)
Considered a subset of Artificial Intelligence, Machine Learning is the application of statistical models and algorithms to solve problems by finding patterns and inferences.
Given the large amount of data being generated in modern times, the objective of ML is for machines to be able to learn from the data itself, without human intervention or assistance. In fact, data is the fundamental basis for all Machine Learning. If there was very little data, or no data at all, the ML algorithms wouldn’t be able to derive useful inferences.
Machine Learning can either be Supervised, Unsupervised, or Reinforced, which we are going to learn more about in further sections.
Therefore, in Machine Learning, the algorithm learns to solve the problem by itself using data, contrasting to a traditional program, where a programmer has to explicitly write a set of instructions. Applications of Machine Learning are in building recommender systems, clustering data points with similar characteristics together (for example, clustering customer data into market segments), or predicting future values based on past data (for instance, predicting stock or market price).
Deep Learning (DL)
Deep Learning is the application of Artificial Neural Networks to imitate the workings of the human brain. It is considered a subset of Machine Learning, because it uses data to learn features, inferences and patterns automatically.
Unlike in Machine Learning, feature engineering, which is an important and difficult step, is automatically taken care of in Deep Learning. In Deep Learning, “deep” layers of Artificial Neural Networks are used to progressively extract higher level features from raw data.
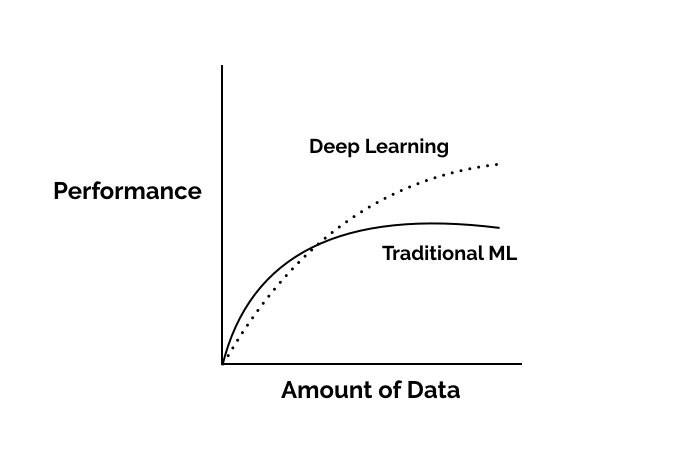
Even though Deep Networks are an older concept, the present growth in Deep Networks has been due to the explosion of data and the availability of more computing power. This is because Deep Learning is computationally expensive, and its accuracy depends on the size of the datasets.
In fact, Deep Learning performance is highly proportionate to data, as compared to other Machine Learning approaches [source]. Some of the applications of Deep Learning are in object recognition, recognition of characteristics from speech or music, & medical image analysis.
Supervised Learning
Supervised Learning is a type of Machine Learning which generates input-output pairs for the ML model based on labeled training data (data containing both input and output parameters). Inferences are drawn using the input-output pairs in the training data and new output values can be predicted using these inferences. Some of the applications are spam detection (where input data is existing spam emails) and optical character recognition (where input data can be labeled images of characters).
Unsupervised Learning
Unsupervised Learning is a type of self-organized learning that helps find previously unknown patterns in an unlabeled dataset (data without pre-existing input-output pairs). The model has to discover information by itself, without the guidance of labels, and so, unsupervised learning is used to do more complex processing. Clustering is the most common application of Unsupervised Learning, which is used to find structure or pattern in uncategorized data. For example, clustering of customers according to purchasing habits, clustering of tissue or organ cells on medical scans.
Reinforcement Learning (RL)
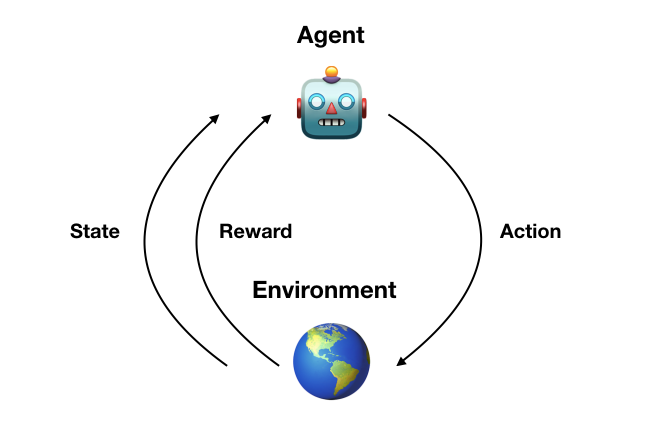
Reinforcement Learning is a class of Machine Learning in which machines optimize their actions in a situation to optimize a “reward” factor. Reinforcement Learning can work with or without training data. In the absence of data, the algorithm learns from its own actions. The focus in Reinforcement Learning is to find a balance between exploration (of uncharted territory) and exploitation (of current knowledge) [source].
Applications of Reinforcement Learning are in training computer systems to play video games or robotics in industrial automation.
Conclusion
We have defined some of the typical Data Science terms and hope that the terminology is getting more clear with the explanations. There are many more terms, which we will discuss in future articles, such as:
- Natural Language Processing
- Computer Vision
- Big Data
- Cloud Computing
- Transfer Learning
- Active Learning
- and more…