
Introduction
Before writing about real-world applications, let’s get a better understanding of Machine Learning first.
Machine Learning (ML) is a field of Artificial Intelligence (AI). The idea is that a computer program can learn and adapt to new data without human interference. But what’s the difference between Machine Learning and Artificial Intelligence? Good question..
Artificial Intelligence refers to the broader concept of simulated intelligence in machines, where machines are programmed to think like a human and mimic the way a person acts. The machine is considered “smart” so to speak. In contrast, Machine Learning is an application of Artificial Intelligence based around the idea to give machines access to data and let them learn for themselves. Especially with the increasing amount of available data, i.e. Big Data, Machine Learning becomes critical for companies and governments to process data and create new insights.
Deepmind’s AlphaGo
In a recent example, Artificial Intelligence/Machine Learning demonstrated its potential:
Perhaps you have heard about AlphaGo, the first computer program to defeat the strongest Go player in history. The program was initially trained on thousands of human games to learn how to play Go. In January 2017, an improved AlphaGo version was revealed as the online player “Master” which achieved 60 straight wins in online fast time-control games against top international Go players.
What’s so special about Go? One of the difficulties comes from the sheer number of possible moves. A 19×19 board offers 361 different places on which Black can put the initial stone. White then has 360 options in response, and so on. The total number of legal board arrangements is in the order of 10170, a number so large it defies any physical analogy (for instance, there are reckoned to be about 1080 atoms in the observable universe). Check out a recent article from The Economist for more details.

The latest evolution of the program is called AlphaGo Zero. It skips the step of being initially trained and learns to play simply by playing games against itself, starting from completely random play. After just three days of self-play training, AlphaGo Zero defeated the previously published version of AlphaGo — which had itself defeated 18-time world champion Lee Sedol. After 40 days of self training, AlphaGo Zero became even stronger, outperforming the version of AlphaGo known as “Master”, which has defeated the world’s best players and world number one Ke Jie.
AlphaGo is developed by the company Deepmind, a subsidiary of Alphabet. Check out their website to learn more about the exciting development. Also, here’s a video where DeepMind’s Professor David Silver describes AlphaGo Zero.
Machine Learning in the Real-World
Video Recommendation
“A lot of times, people don’t know what they want until you show it to them.” (Steve Jobs)
In general, recommendation engines are powerful personalization tools because they help to discover items that people might have not discovered by themselves. Consequently, recommendation engines improve the overall user experience by offering relevant content at the right time and generate additional revenue for the company. Gomez-Uribe and Neil Hunt of Netflix wrote in a paper (The Netflix Recommender System, 2016) that over the years, the recommendation system has decreased customer churn by several percentage points and saves the company about $1 billion a year.
According to the authors, Netflix takes advantage of the large amounts of data from the digital consumption of video content and feeds the data into several algorithms powered by statistical and Machine Learning techniques. Approaches use both supervised (classification, regression) and unsupervised (dimensionality reduction through clustering or compression) approaches.
Speech Recognition
All big five tech companies are working on bringing speech recognition to consumers:
- Apple => Siri
- Alphabet => Google Now
- Microsoft => Cortana
- Amazon => Alexa
- Facebook => Oculus Voice
Speech recognition is the ability of a machine to identify words and phrases in spoken language and convert them to a machine-readable format. The most frequent applications of speech recognition include call routing, speech-to-text processing, voice dialing and voice search. What makes speech recognition so hard is the huge amount of variation that occurs while pronouncing a word. For example, regional accents and speech limitations can throw off word recognition programs, and background noise can be difficult to deal with. Also, think about ordering “ice cream” or saying “I scream” — it’s hard for a machine to understand what you mean.
As Andrew Ng, Co-Founder of Coursera, puts it: “As speech-recognition accuracy goes from 95% to 99%, we’ll go from barely using it to using all the time!”. The 4% accuracy gap is the difference between annoyingly unreliable and incredibly useful.
Fraud Detection
The rate of fraud is increasing worldwide; especially due to the rising number of online accounts and transactions. For example, financial fraud such as credit card fraud and identity theft results in yearly losses that goes into billions of dollars.
The good news, however, is that more data generated by online transactions also means more opportunities to identify suspicious behavior and tackle fraudulent activities. The traditional approach to tackling this problem is to use rules or logic statements to query transactions and to direct suspicious transactions through to human review. Unfortunately, it’s pretty slow, costly and inflexible.
Why is Machine Learning more effective to solve the problem of fraud? Machines are much better than humans at processing large datasets. Therefore, the alternative is to leverage the vast amounts of data that are collected from online transactions and build a model that allows to flag or predict fraud in future transactions. Machine Learning programs are able to detect and recognize thousands of patterns instead of the few captured by the traditional rules-based system.
Medical Diagnostics
Medical diagnostics describes medical tests that determine which disease or condition explains a person’s symptoms and signs. Its goal is to detect infections, conditions and diseases. Traditionally, diagnosing diseases has been one of the more labor intensive aspects of the healthcare system; and it is a challenging one, because signs and symptoms are ambiguous. Take the example of redness of the skin: it can be a sign of many disorders and thus doesn’t tell the doctor what is wrong.
However, thanks to massive volumes of patients data, Machine Learning is perfectly suited to make better diagnoses and more accurate predictions. Much of the diagnostic data is image-based, such as X-rays, MRI scans, and ultrasound imagery, but can also include things like genomic profiles, epidemiological data, blood tests, biopsy results, and even medical research papers. As a result, there is a wealth of data available for Machine Learning techniques.
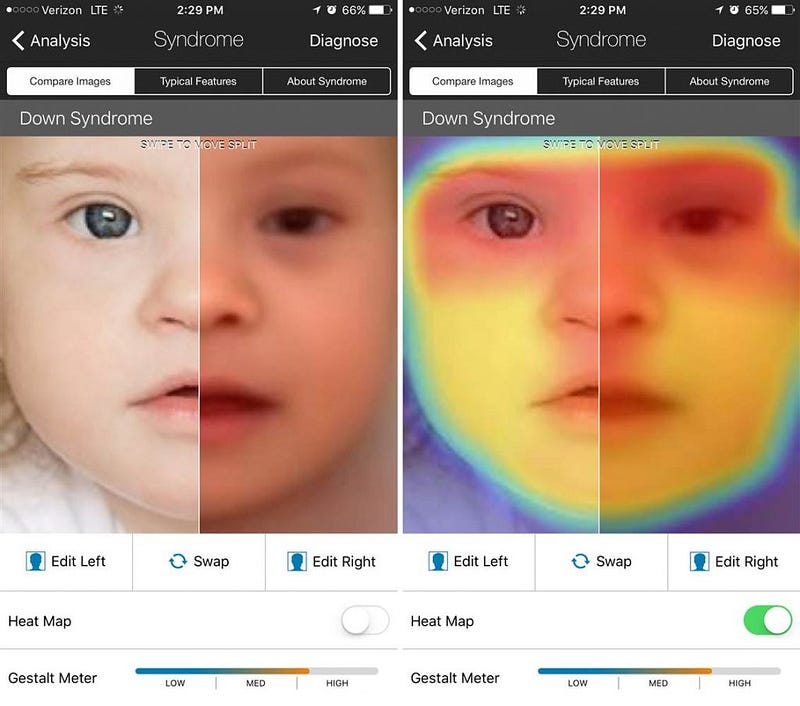
Source: FDNA, Facial recognition app Face2Gene
Here’s a good real-world example: The Face2Gene app, developed by company FDNA, is a facial recognition software that uses a photo to identify syndromes and diseases. The Machine Learning algorithms map points on a patient’s face, compare those points with a database containing points from thousands of other faces, and suggest potential diagnoses. Although the software doesn’t replace a professional healthcare provider’s judgment or experience yet, it can help to narrow down the possibilities and support the decision making process.
Self-Driving Cars
It’s probably one of the most profound changes from a consumer perspective: the transition to self-driving cars. Those vehicles will be capable of sensing the environment and navigating without a human driver behind the wheel.
There’s a lot information available about the development, opportunities, and challenges of autonomous vehicles, so let’s just highlight how Machine Learning comes into play. There’s large amounts of data generated through systems such as the LIDAR unit, cameras, and radar sensors in a car that is supposed to drive on its own, and one of the major tasks of Machine Learning algorithms is to analyze the data and forecast the changes that are possible to the environment. Steps include things such as:
- The detection of an Object
- The Identification of an Object or recognition object classification
- The Object Localization and Prediction of Movement
There’s a lot of companies working on solving the big problems that are still ahead before self-driving cars are ready for mass market. Companies that come to mind are all big automobile manufactures, Uber, Tesla, Google; just to name a few. Another one is Drive.ai, a Silicon Valley startup that is creating AI software for autonomous vehicles using Machine Learning/Deep Learning methodologies. Check out their video about a rainy night in a self-driving car. Pretty cool!